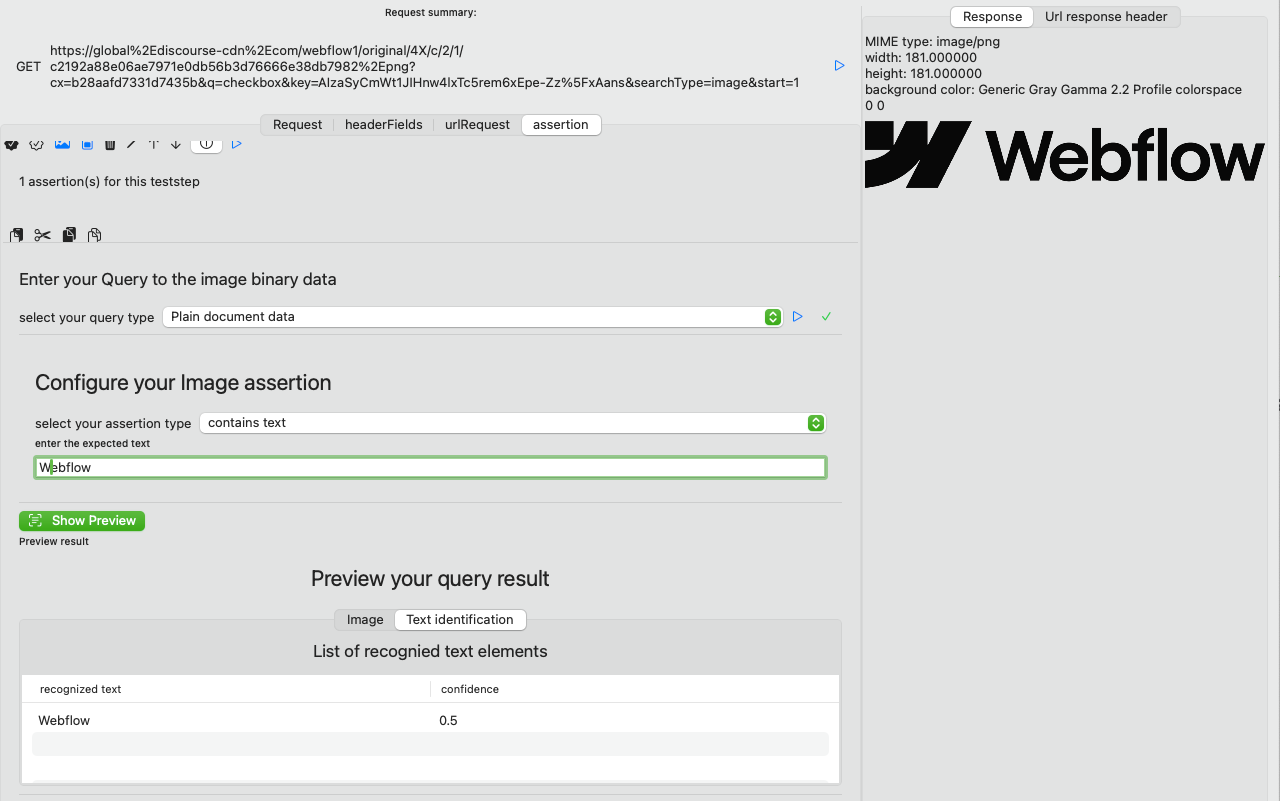
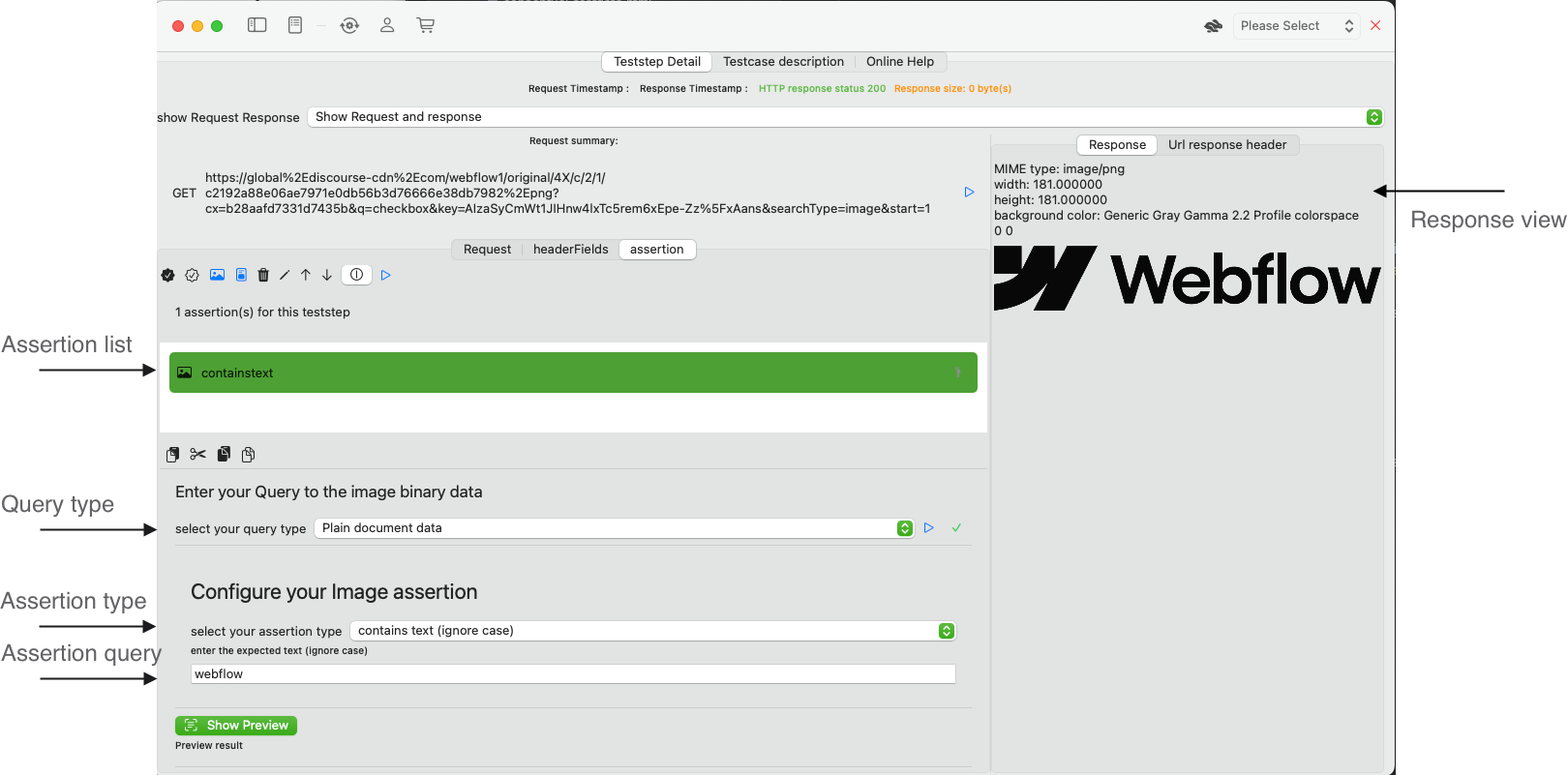
Image Assertion editor
An Image assertion uses a trained machine learning model to capture the text contents of a file.
Query Type
As a first step, you need to configure, where the image data should be taken from. There are four options:
- JSONPath, enter the JSONPath expression to the binary data in the response that represents the image.
- XPath 1 (with function support), enter the XPath expression to the binary data that represents the image. Note: If you work with MTOM, you will need to select the href attribute which holds the content-ID reference.
- XQuery / XPath 2 (no function support), enter the XPath expression to the binary data that represents the image.
- Plain Document data, the response is expected to hold binary data that represent the image.
Configure your Image assertion
You have three options to check Text content on an image
- Contains text enter the expected text.
- Contains text (ignore case), enter the expected text.
- Barcode, enter the expected payload
The blue run button together with the result status (green checkmark) validates the assertion and gives you immediate feedback.
Preview
When you run the query (blue run button), APIJockey TEST will try to read the Image data, supported types are TIFF, PNG, JPEG, GIF and PDF. IF this is successful you will see the received image in the preview, together with the assertion run results as in the screenshot below:

Query result
It seems odd that both preview and response view show the same content. This is the case as the response contains the image only. In other cases you might have a JSON Response or a SOAP Response and would apply JSONPath, XQuery or XPath to extract the Base64 encoded data, which would then internally be transformed to binary image data. If this is the case, you will see another tab Query Result that should help you identify, what part of the response document is returned by your query.
Text/Barcode identification
When the assertion run is completed you will see a tab Text identification or Barcode identification depending on your Assertion type. This tab holds a list of Texts / Barcode payload found during the AI-scan together with a confidence vote. This can help you decide, if you want to run the assertion automatically or manually only, as a low confidence vote might be an indicator for a hit that is on reliably reproduceable. Also keep in mind that ML-model are non-deterministic. In our sample, the text identification gives these results: