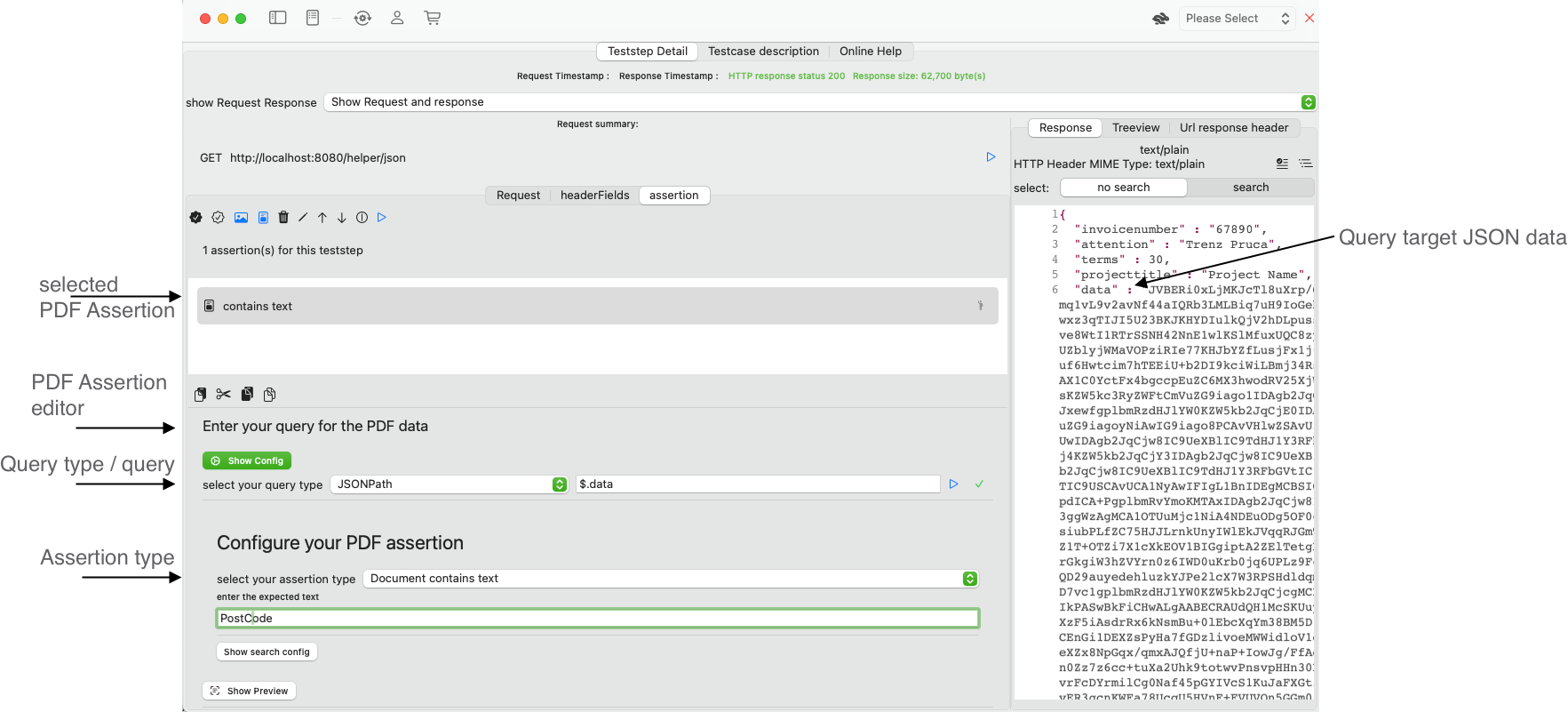
PDF Assertion editor
A PDF Assertion verifies, if a text appears in a PDF-File.
Query Type
As a first step, you need to configure, where the image data should be taken from. There are four options:
- JSONPath, enter the JSONPath expression to the binary data in the response that represents the PDF.
- XPath 1 (with function support), enter the XPath expression to the binary data that represents the PDF. Note: If you work with MTOM, you will need to select the href attribute which holds the content-ID reference.
- XQuery / XPath 2 (no function support), enter the XPath expression to the binary data that represents the PDF.
- Plain Document data, the response is expected to hold binary data that represent the PDF.
The blue run button together with the result status (green checkmark) validates the assertion and gives you immediate feedback.
Configure your PDF assertion
You have several assertion types to verify a PDF document
- Number of pages where you enter the expected page count.
- Document contains text on page (number) where you enter the expected text and the page nr.
- Page (number) has label where you enter the expected text and the page nr.
- Document is locked where you provide if the flag must be TRUE or FALSE
- Document is encrypted where you provide if the flag must be TRUE or FALSE
- Document allows copying where you provide if the flag must be TRUE or FALSE
- Document allows printing where you provide if the flag must be TRUE or FALSE
- Document allows commenting where you provide if the flag must be TRUE or FALSE
- Document allows inserting, deleting or rotating where you provide if the flag must be TRUE or FALSE
- Document allows changes (expect document attributes) where you provide if the flag must be TRUE or FALSE
- Document allows form field entries where you provide if the flag must be TRUE or FALSE
Search Options
When you select assertion types that search for text, you have to search options:
- case insensitive
- literal (read character by character)
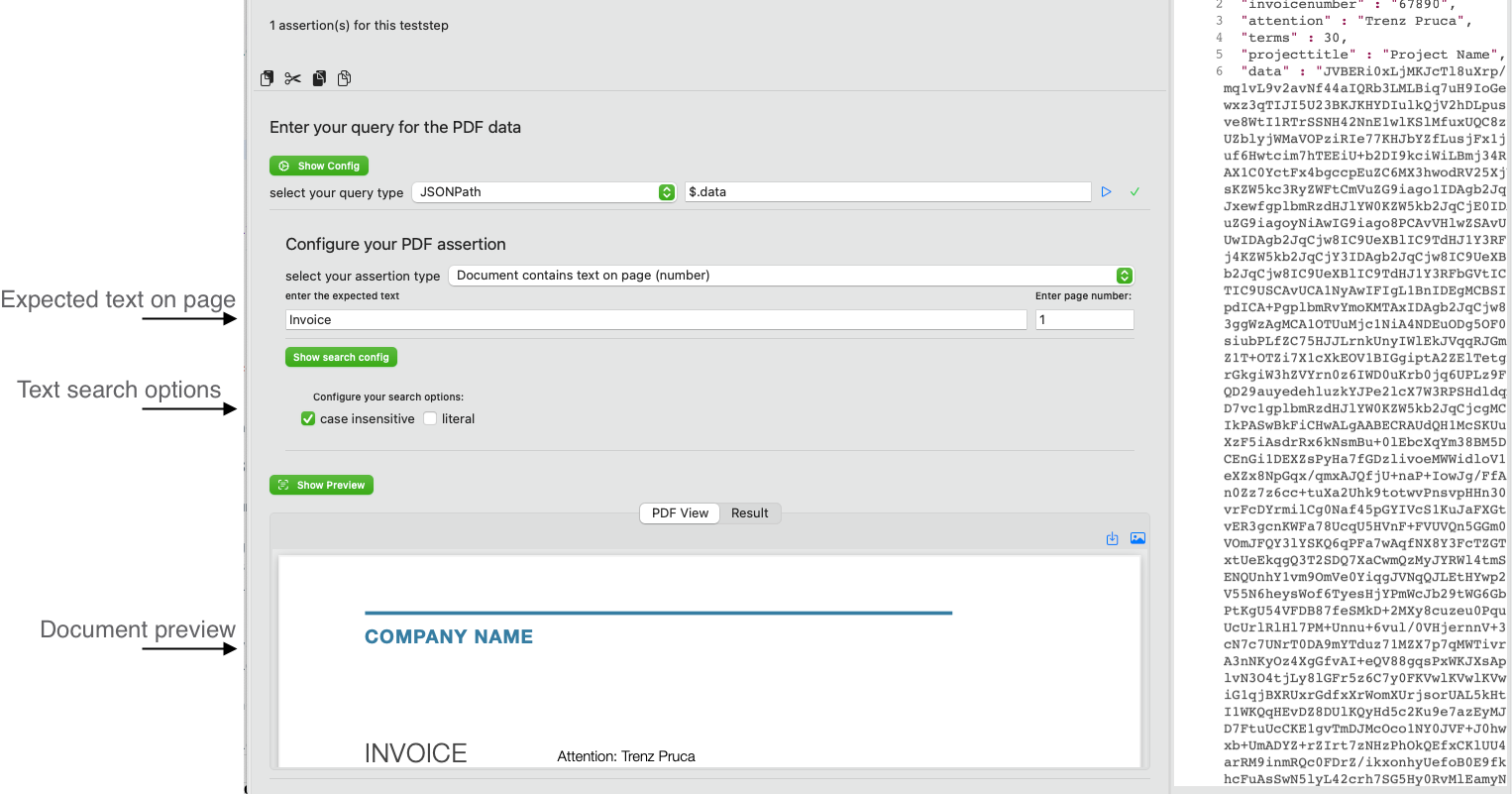
Preview your query
When you run the query (blue run button), APIJockey TEST will try to run the query against the response. If this successful, the data will be used to interprete it as base64-encoded PDF data, if you query with JSONPath, XQuery or XPath. I. IF the query is set to Plain document data the response data is interpreted as plain PDF data. If reading the data and interpreting as PDF is successful, the PDF document appears in the tab PDF View, together with the base64-encoded query result in the tab Result, which may help you to fine-tune your query expression.